It’s the age-old question in UX testing circles: how many user testing participants should I test with? Luckily for you, the Userbrain team has put some thought into it, and we’re here to help you make the right call.
How long is a piece of string?
Imagine that you have a porcelain store. One day a piercing scream rings through the shop, followed closely by that feared sound of things breaking on the floor. When you get to the place, you find an upset elderly lady amid a sea of broken crockery that was once your most exclusive tea set on display. You have somebody immediately remove the pile of broken fragments and start looking for the cause of this unfortunate event.
You notice that the carpet has come loose near the accident, creating a slight crease. You’ve never noticed this crease before, and at first glance, it appears to be relatively inconspicuous. But apparently it was enough to make an old lady stumble. What could you do now?
Possibility No. 1: You have the carpet repaired and wait to see if, after the repair, another customer ends up in the same place – in a sea of broken china.
Possibility No. 2: You wait to see if at least 36 other customers have the same accident to observe a representative number of cases and be able to say, with statistical significance and absolute certainty, that there is indeed a problem.
The purpose of user testing is to observe the behavior of people who use your product, identify usability problems, fix them, and improve your product. As mentioned, we are not concerned with the opinions of individual persons, and therefore we don’t need a statistically relevant number of user testing participants. In user testing (as in focus groups or interviews), we’re dealing with a qualitative method (observing a behavior) and not with a quantitative method (collecting opinions). During user tests, we simply observe our testers while using our product and try to identify the cause of the problems our product may have. And that’s something usually relatively easy once we become aware of the problem.
Qualitative testing will improve your product
Product teams often shy away from qualitative methods because they don’t seem to be “sufficiently scientific”. After all, a bar graph with percentages in a PowerPoint presentation looks a lot “truer” than referring to a single tester who had problems in the most recent user test. But how much does quantitative data actually help you if your goal is to improve your product? If you know that 85% of your users complete the checkout process in under five minutes – is that a good or bad thing? For this quantitative data to be of value, you would need to know comparative values and, for example, test other web pages or different variants of your product. And this effort is usually not effective:
If your goal is to understand human behavior to make design decisions, qualitative methods are much more effective in providing you with the information you need.
– Kim Goodwin in “Designing for the Digital Age”
For this reason, we also recommend not losing time measuring usability. Our goal is to observe human behavior when interacting with our product, thereby identifying errors in our solution and understanding the cause of usability problems. Sometimes you need two, three, or even more, testers to actually identify the problem. Still, if you can figure out the cause of the problem (the carpet crease) after observing just one tester, you can fix this problem immediately and check if it’s actually been solved with another round of testing. And for such a procedure, a handful of user testing participants per round will suffice.
Okay! But how many user testing participants are actually enough?
We were afraid this answer wouldn’t seem enough for you. Therefore, let’s delve deeper into this because defining the perfect number of user testing participants remains a popular debate among usability experts. Steve Krug, the author of the usability bestseller, Don’t make me think! recommends testing with three testers per round.
His reasons include the following:
- Finding three testers is less work than searching for more;
- Doing more than three tests in a single day means getting snacks for the people who moderate the tests and also for those who watch the tests;
- If you test with three user testing participants, you can do your tests and present the results on the same day.
Following Steve Krug’s quote, many people plunge into a user test with three testers. If Steve Krug says it, what can go wrong? Honestly? Not much. Nevertheless, let’s clarify a few things that are often overlooked when following Steve Krug’s suggestion:
Steve Krug recommends three tests per round. Per round means that we test more than just once. He also refers to moderated and onsite user tests in his recommendation, so many of his arguments are based on the extra effort that further tests of this kind would cause. After all, in these moderated tests, somebody has to find suitable testers, plan the test dates jointly with them, and then conduct and moderate every single test. While we strongly recommend conducting moderated user tests, they can take an amount of time and effort to set up. And, in the immortal words of an internet sensation, ain’t nobody got time for that.
Since we describe in our book how user testing really works in practice and suggest unmoderated remote user tests, this argument doesn’t apply in our case. Why? Because user testing platforms, such as Userbrain, typically take over the search for new testers, and the testers simply moderate themselves. So whether you would like one tester or 100,000 testers, finding participants for your user tests is stress-free with Userbrain’s approach.
It’s also worth noting that Steve Krug started doing user tests more than 20 years ago. His book, where he initially made the ‘three testers’ proposal, is already more than 13 years old and was published before the iPad was launched. There has been a tremendous technological advance in recent years, and we now have to make sure that our digital products can be used on desktops as well as on smartphones, tablets, smartwatches, and other devices. And, with that, we must consider additional influences that affect the behavior of our users. After all, you use an online store on your smartphone (short sessions, which are often interrupted) differently than on your desktop computer (longer sessions, often with a more systematic approach). Thus, three testers are seldom enough for our requirements – not if you want to gain real, tangible insights into your product.
The law of diminishing marginal returns with user test participants
If we continue to search for the perfect number of testers for user testing, we’ll soon stumble upon a curve by Jacob Nielsen – another well-known name in the context of usability. In 2000, Jacob Nielsen published a statistic that has been circulating in UX research circles ever since:
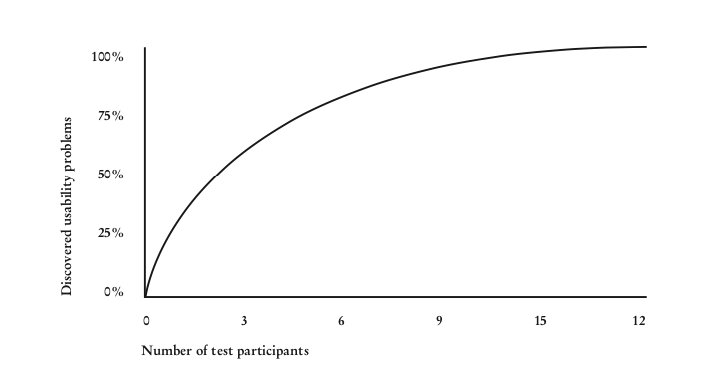
On the X-axis of this graph, we see the number of user testing participants, while the usability problems are displayed as percent on the Y-axis. What’s immediately striking is that the number of detected usability problems rises sharply up to the first three testers.
With three testers, you will find that each tester discovers many new usability problems; there tends to be little correlation between their insights. However, the number of new insights decreases progressively with six tests or more, and after the twelfth test, you’ll discover virtually no new usability issues.
What we have here is the law of diminishing marginal returns. At some point, new inputs (new testers) only provide minimal additional output (new usability problems). So the perfect cost/benefit ratio in user testing lies somewhere between the third and sixth tester in a testing round.
What Jacob Nielsen is showing us with this graph is that from an economic point of view, it makes more sense to test with a smaller number of testers (about three to six per round), fix the discovered problems immediately and then conduct further testing, rather than conducting individual test runs with a larger number of testers.
 While Krug and Nielsen recommend a different number of testers, they agree on one thing: It’s rather less about how many people you should test with and more about how user testing should be an ongoing activity. More important than finding the exact number of perfectly matched testers is to conduct your user tests regularly. And to achieve this, you need the pool of available testers to be as large and diverse as possible.
While Krug and Nielsen recommend a different number of testers, they agree on one thing: It’s rather less about how many people you should test with and more about how user testing should be an ongoing activity. More important than finding the exact number of perfectly matched testers is to conduct your user tests regularly. And to achieve this, you need the pool of available testers to be as large and diverse as possible.
Userbrain offers over 100,000 testers – more user test participants than you’ll ever need
That’s right. With a Userbrain subscription, you will have round-the-clock access to over 100,000 quality-assured user testers. Starting at just $99 a month, there has never been a better time to get into the habit of regular, consistent user testing. Your customers will thank you for it!
We offer a variety of different packages, so whether you need three, ten, or 30 testers per month, Userbrain has you covered.

And if that’s not enough to satisfy your itch, make sure to give us a call, and we can tailor a more extensive package to meet your needs.
We hope this article has helped you to work out how many user testing participants you need for your next test.
Remember, you can get started at Userbrain with your first two tests for free. Start your free trial now!
